Prozessdigitalisierung für mittelständische und große Unternehmen
Mit uns als Digitalisierungsstrategen an Ihrer Seite ärgern Sie die komplexen Strukturen in Ihrem Unternehmen nicht länger – Sie konvertieren diese in smarte, digitale Prozesse, die Sie entlasten und Ihnen dabei helfen, Ihre Ziele schneller zu erreichen.
Kostenloses Erstgespräch vereinbaren
Prozesse verstehen. Software entwickeln.
Laut einer aktuellen Studie werden in zwei von drei deutschen Großunternehmen dringend notwendige Veränderungen durch eingestaubte Prozesse blockiert. Außerdem stehen in jedem zweiten Unternehmen veraltete IT-Systeme und eine überholte Firmenkultur erforderlichen Optimierungen im Weg. Diese Entwicklungen zeigen: Technologien und Prozesse gehören zusammen und eine Isolierung kann fatale Folgen haben.
Deshalb verbinden wir Softwarelösungen mit einem fachspezifischen Consulting-Angebot – unser Garant für erfolgreiche Digitalisierungsprojekte mit messbaren Ergebnissen.
Consulting-Angebot mit Realitätsbezug
Egal ob BI, Finance, HR, Projektmanagement, Supply Chain Management oder Vertrieb: Mit steigender Komplexität stößt Standard-Software wie MS Excel früher oder später an ihre Grenzen. Die Folgen: Ein großer manueller Aufwand und steigende Fehlerquoten.
Das kommt Ihnen bekannt vor? Dann wird es Zeit für eine professionelle Lösung! Lassen Sie uns gemeinsam smarte Prozesse entwickeln, die wir im Anschluss digital abbilden und so wertvolle Kapazitäten zurückgewinnen.

Ja, ich möchte meine Prozesse optimieren
Gespräch vereinbaren
Softwarelösungen the smart way
Bedürfnisorientierte Prozessdigitalisierung in Lichtgeschwindigkeit!
Was haben Sie von einer Unternehmenssoftware, die Ihren Schmerz im Ernstfall nicht löst? Partake verstärkt Sie mit dem notwendigen Know-how, um eine praxistaugliche Lösung für Ihr Problem zu finden, die Hand in Hand mit Ihrer bestehenden IT-Infrastruktur geht.
Unsere Trademarks





Ja, ich möchte eine Softwarelösung entwickeln lassen
Gespräch vereinbaren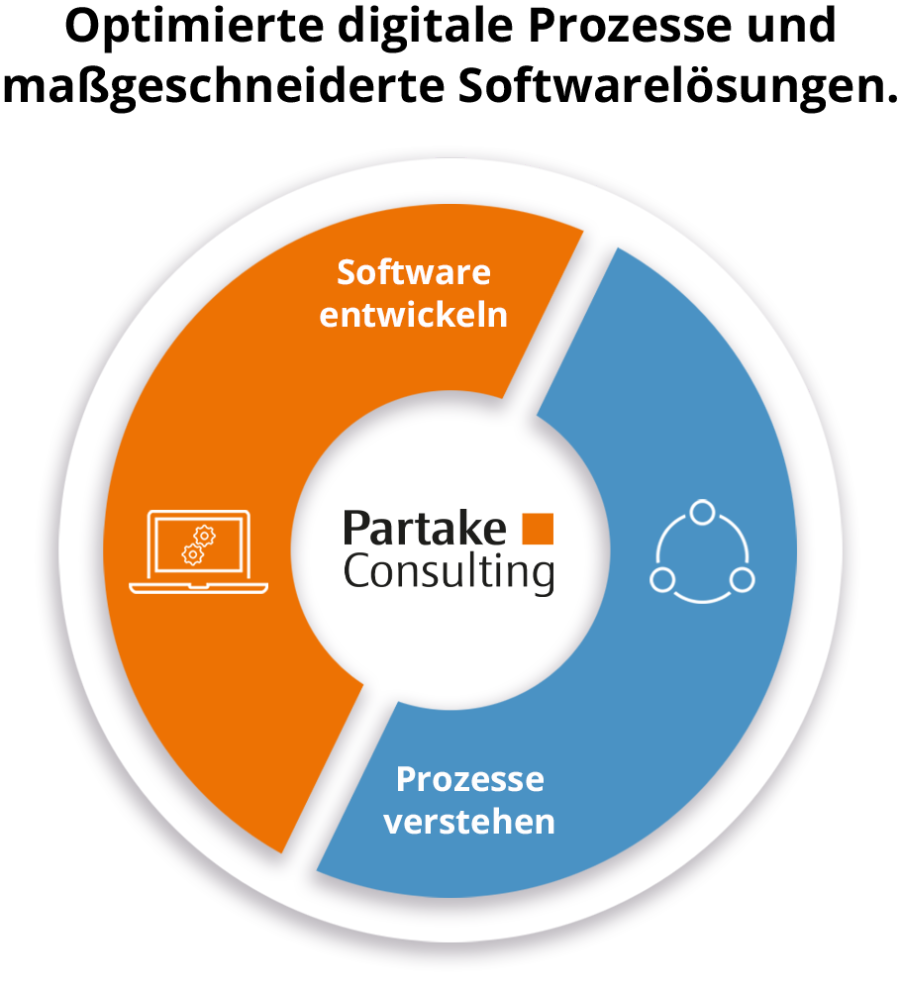
Das sagen unsere Kunden
EnBW
Joachim Fies | Head of BI in Group Controlling
Unsere Projekte erfordern ein sehr hohes Maß an Kundenorientierung, Qualität und Zuverlässigkeit. Genau deshalb setzen wir mit Partake auf einen langjährigen Partner. Neben hoher Flexibilität schätzen wir die Kombination zwischen fachlichem und technischem Know-how in einer sehr ausgeprägten Form.
Studierendenwerk
Michael Dahlhoff | Geschäftsführer
Wir haben uns für Jochen Brühl (GF) und sein Team entschieden, da mich ihre Expertise im Rahmen einer jahrelangen Zusammenarbeit in früheren Projekten überzeugt hat. Mithilfe der Low Code-Plattform ihres Technologiepartners nedyx® können wir unsere Digitalisierungs-Roadmap vorantreiben.
Mittelständisches Maschinenbauunternehmen
Jürgen J. | Abteilungsleiter IT
Wir hatten in unserem BI- und Planungsprojekt hohe Ansprüche an eine optimale und moderne IT-Lösung. Mit Partake haben wir einen Partner gefunden, der unsere Probleme versteht und zu lösen weiß. Seit vielen Jahren ist die Zusammenarbeit geprägt von Professionalität und Zuverlässigkeit.
Ein Team, ein Weg
Partake ist die erste Adresse für mittelständische Unternehmen und Global Player, die nach einem strategisch denkenden Digitalisierungspartner suchen. Unser Team verbindet eine gemeinsame Leidenschaft: Für Unternehmen unterschiedlichster Branchen pragmatische Lösungen zu schaffen. Komplexität aufzulösen. Das scheinbar Unmögliche möglich zu machen.
Klingt spannend? Hier verraten wir Ihnen mehr über unsere Werte, Methoden und Lösungsansätze.


Digitize The Future Now
Als verantwortliche Person auf C-Level-Ebene bekommen Sie es jeden Tag zu spüren: Die internen Prozesse in Ihrer Abteilung sind einfach nicht mehr zeitgemäß. Sie wünschen sich mehr Automation und zeitgemäße Workflows, um Ihren eigenen manuellen Aufwand zu reduzieren? Dann sind Sie bei Partake genau richtig!
In einem Gespräch zeigen wir Ihnen gerne, mit welchen Lösungen wir unseren Kunden in den vergangenen 16 Jahren in vergleichbaren Situationen geholfen haben und wie wir die Digitalisierung von Geschäftsprozessen auch in Ihrem Unternehmen erfolgreich gestalten.
Gespräch vereinbaren
Wählen Sie den gewünschten Termin aus und vereinbaren Sie ein unverbindliches und kostenfreies Kennenlerngespräch mit Dieter Höfer (Partner & Mitglied der Geschäftsführung). Gerne gehen wir auf Ihre Fragen ein und besprechen Lösungswege für Ihre individuellen Anforderungen.
FAQs zur Prozessdigitalisierung
 Was bedeutet der Begriff Prozessdigitalisierung genau?
Was bedeutet der Begriff Prozessdigitalisierung genau?
Bei der Prozessdigitalisierung sehen wir uns an, mit welchen Technologien ein Unternehmen seine Arbeit noch besser und effizienter erledigen kann.
Dafür entwickeln wir gemeinsam mit unseren Kunden Strategien und Workflows, die den manuellen Aufwand von Mitarbeitern reduzieren und bilden diese in digitalen Anwendungen, Strukturen und Systemen ab.
So stärken wir den Automatisierungsgrad, fördern die Standardisierung von Abläufen, verbessern die Zusammenarbeit in den Teams und erhöhen die Datenqualität.
Wie wichtig ist die Digitalisierung von Prozessen für mein Unternehmen?
Digitalisierte Prozesse bringen viele Vorteile: Sie stärken die Wettbewerbsfähigkeit von Unternehmen, weil sie Arbeitsabläufe beschleunigen, Effizienz steigern, Engpässe beseitigen und sogar Kosten reduzieren.
Durch die Digitalisierung von Prozessen sind Sie in der Lage, Daten schneller und besser zu verstehen. Routineaufgaben erfordern weniger manuellen Aufwand, weil sie ab sofort voll automatisiert abgearbeitet werden. So greift ein Zahnrad ins andere und Sie haben eine bessere Grundlage für eine fundierte Entscheidungsfindung.
Warum sollte ich mich für Partake entscheiden?
Mit Partake bekommen Sie einen spezialisierten Digitalisierungsexperten und Anwendungsberater in einem. Wir erarbeiten nicht nur Strategien und Konzepte. Unser Team kümmert sich auch direkt um die technische Umsetzung – in Form von maßgeschneiderten Lösungen zur Prozessdigitalisierung, die Ihren Arbeitsalltag effizienter gestalten.
Durch unseren objektorientierten Ansatz profitieren Sie von einer besonders schnellen Umsetzung. Bei der Problemlösung setzen wir auf bewährte Methoden wie Business Process Management (BPA) und Robotic Process Automation (RPA).
Vorausgesetzt es passt zu Ihrer Problemstellung, arbeiten wir auch gerne mit innovativen Technologien wie beispielsweise IoT (Internet of Things) oder künstlicher Intelligenz (KI). Außerdem sind wir in der Lage, smarte ERP-, CRM- und Workflow-Management-Systeme zu entwickeln.
Ist Partake der richtige Partner für meine Branche oder Abteilung?
Partake steht für ein auf mittelständische und große Unternehmen spezialisiertes Consulting-Angebot und Anwendungsberatung. Unser Alleinstellungsmerkmal ist eine besonders ausgeprägte fachliche Expertise in folgenden Bereichen:
- Planung
- Reporting
- Datenintegration
- Data Warehouse
- Finanzen & Controlling
- Vertrieb & Marketing
- Supply-Chain & Einkauf
- Human Resource Management
- BI & Advanced Analytics
- Projektplanung/Projektmanagement
Sie sind sich unsicher, ob wir Ihnen bei Ihrer Problemstellung weiterhelfen können? Dann nehmen Sie einfach Kontakt zu uns auf und wir sehen uns gemeinsam Ihre Anforderungen an.